
B2B buyers no longer rely on Google alone. Increasingly, they also use ChatGPT as a strategic sounding board: to understand a complex term, to explore an approach, or to compare different software solutions. That raises a relevant question for every B2B marketer: how does ChatGPT actually decide which brand to mention, and which sources does it use to build that answer?
For this article, I looked at data from Quolity, a tool that monitors what happens under the hood of ChatGPT and reveals which external websites and search queries the model itself uses to construct an answer. That’s what makes it interesting. I’m not just looking at what a user asks ChatGPT, but especially at what ChatGPT does next. And that’s precisely where you can see how visibility in AI-generated answers actually works.
The Basics: Data, Methodology, and Perspective
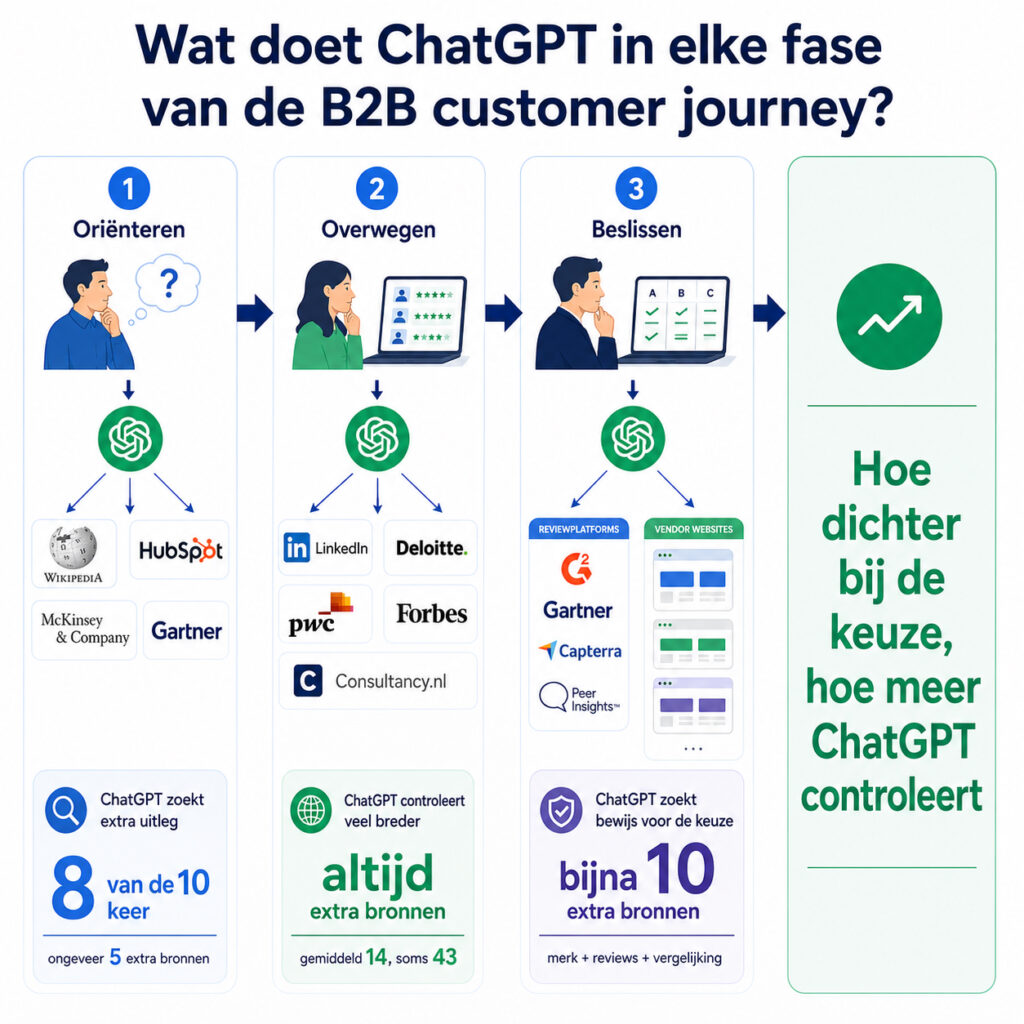
For this initial analysis, I used exclusively Quolity JSON exports. I deliberately kept CSV and XLSX overviews and other provider exports out of scope, so I could base the analysis entirely on Quolity source data. The dataset consists of 533 prompt runs, based on 177 unique B2B prompts. What immediately stands out is that fan-out — ChatGPT independently searching for external sources — is not the exception but the norm. In 91.7% of all runs, the model showed fan-out behavior.
I like to read that data through the lens of the B2B customer journey, because it makes ChatGPT’s behavior much more concrete. Not every question triggers the same search path. The closer a question gets to validation, comparison, or expert selection, the more extra search steps the model typically takes. That makes fan-out not just a technical phenomenon, but also a useful marketing framework.

Phase 1: Awareness
In the awareness phase, I mostly see definitions and knowledge questions. Think of queries like: what is supply chain optimization? or how does employer branding work? For these broad questions, ChatGPT partly relies on existing model knowledge, but the data also clearly shows that the model frequently seeks external validation. For definition queries, it showed fan-out in 82.4% of runs, with an average of 4.7 extra searches per run.
What stands out is that ChatGPT often looks for recent context and sources that explain a topic clearly. In the underlying query families, I regularly see patterns like trend_year and site_search. This suggests the model doesn’t just want to provide a standard definition, but wants to update or verify its answer using recent and targeted sources.
The marketing lesson at this stage seems clear to me. When someone is still in the awareness phase, my website or content needs to function as a reliable knowledge base. Clear definitions, current context, and well-structured explanatory content help not just for SEO or thought leadership, but also increase the likelihood that ChatGPT uses my content to cross-check and supplement its baseline knowledge.
Phase 2: Consideration
In the consideration phase, ChatGPT’s behavior shifts noticeably. Here I see far more questions about experts, consultants, specialized parties, and organizations with visible authority. For example: who are the leading independent HR consultants? These types of prompts is exactly where AI search behavior peaks. Expert queries triggered fan-out in 100% of runs in my dataset, with an average of 13.7 extra searches and a maximum of 43 in a single run.
What I find interesting is that the model doesn’t simply follow one type of source. Company and vendor sites remain important; within expert runs, 53.3% of measured source types fall in the company_or_vendor_site category. At the same time, there’s a clear mix with personal profiles, consultancy sites, and trade media. Personal profiles account for 16.9% of measured source types under social_profile, consultancy sites at 10%, and trade media at 9.9%. LinkedIn appears regularly in these search paths, but never as the sole or dominant source of truth.
That’s why I’m not drawing a simplistic conclusion like “only personal branding matters” at this stage. What I do see is that a company website alone isn’t enough. To be visible in the consideration phase, my brand needs to be linked to recognizable experts, publications in trade media, and presence on professional networks. ChatGPT doesn’t just seem to be looking for a company name here, but rather for a credible mix of expertise, recognition, and external confirmation.
Phase 3: Decision
In the decision phase, ChatGPT’s search behavior becomes even more concrete. Here I mainly see comparison queries, such as: how does software A compare to software B? These prompts activate a clear validation path. Comparison queries trigger an average of 9.48 extra searches per run. That’s less than for expert queries, but still significant.
What I primarily see in this phase is that ChatGPT doesn’t reject vendor content, but doesn’t let it stand alone either. Within comparison runs, 73.3% of measured source types remain vendor-driven, yet G2, Gartner, Capterra, and Peer Insights consistently appear in the raw fan-out queries. This means the model tries to triangulate vendor information with independent or semi-independent validation. It’s not just looking for what a brand says about itself, but also for what third parties show.
That’s precisely where the most important marketing lesson of this phase lies. My own product pages remain important — ChatGPT uses those too. But without visibility on review platforms, comparison sites, and analyst environments, I’m missing an essential part of the path through which the model builds trust. In AI visibility, it’s not just about owned media, but also about the places where my brand is reflected, compared, and validated by others.
Are There Differences Between B2B Industries?
There are, but smaller than I might have expected. In the dataset, I looked at domains like GEO, SaaS, Supply Chain, HR, and Marketing. I see nuanced differences, but no fundamentally different logic. GEO, for example, has a trigger rate of 97.8%, while Supply Chain sits at 87.5%. That’s relevant, but not the main story.
The pattern I see everywhere is that prompt intent carries more weight than industry. A comparison question about HR software activates essentially the same validation logic as a comparison question about logistics software. An expert query in SaaS looks much more like an expert query in HR or GEO in terms of search behavior than it resembles a definition query within that same SaaS sector. For me, that’s an important insight, because it means I shouldn’t approach AI visibility purely by market, but especially by the type of question and the stage in the journey.
The Logic Behind the Behavior: An E-E-A-T-Like Lens
Based on this dataset, I can’t prove that ChatGPT literally follows a fixed evaluation model. What I do see is that the fan-out patterns strongly resemble an E-E-A-T-like logic: Experience, Expertise, Authoritativeness, and Trustworthiness. I find that comparison with Google useful, not because it’s the same system, but because it helps make ChatGPT’s behavior understandable.
When the model combines vendor sites with personal profiles, I see a search for expertise. When it uses review platforms and comparison environments, that points to experience and trust for me. And when it searches specifically within trusted domains via site_search, I see in that a preference for sources with perceived authority. So I wouldn’t say ChatGPT “applies E-E-A-T” in a literal sense, but the search behavior strongly points to a comparable validation logic.
My Conclusion
When I bring this analysis down to one practical conclusion, it’s this: becoming visible in ChatGPT doesn’t require a single trick, but a layered approach. In the awareness phase, my domain needs to function as a current knowledge base. In the consideration phase, my experts, consultants, or thought leaders need to be visible beyond my own site. And in the decision phase, my brand needs to appear in independent review and comparison contexts.
That combination is what makes the difference, I believe. ChatGPT doesn’t just look at what I publish myself, but also at how my brand comes back in the broader web of expertise, validation, and trust. The better those layers align, the greater the chance that the model ultimately presents my brand as a credible and useful answer.