B2B-kopers Googelen niet meer alleen. Steeds vaker gebruiken ze ChatGPT ook als strategisch klankbord: om een ingewikkelde term te begrijpen, om een aanpak te verkennen of om verschillende software-oplossingen tegen elkaar af te wegen. Dat roept een relevante vraag op voor iedere B2B-marketeer: hoe beslist ChatGPT eigenlijk welk merk het noemt, en welke bronnen het gebruikt om tot dat antwoord te komen?
Voor dit artikel heb ik gekeken naar data uit Quolity, een tool die onder de motorkap van ChatGPT meekijkt en zichtbaar maakt welke externe websites en zoekopdrachten het model zelf gebruikt om een antwoord op te bouwen. Juist dat maakt het interessant. Ik kijk hier dus niet alleen naar wat een gebruiker aan ChatGPT vraagt, maar vooral naar wat ChatGPT daarna zelf gaat doen. En precies daar wordt duidelijk hoe zichtbaarheid in AI-antwoorden werkt.
De basis: cijfers, verantwoording en invalshoek
Voor deze eerste analyse heb ik uitsluitend Quolity JSON-exports gebruikt. CSV- en XLSX-overzichten en andere providerexports heb ik bewust buiten scope gelaten, zodat ik de analyse volledig op de Quolity-brondata kon baseren. De dataset bestaat uit 533 prompt-runs, gebaseerd op 177 unieke B2B-prompts. Wat daar direct uit springt, is dat fan-out — het zelfstandig zoeken naar externe bronnen door ChatGPT — geen uitzondering is maar normaal gedrag. In 91,7% van alle runs liet het model fan-out zien.
Ik lees die data graag door de lens van de B2B customer journey, omdat dat het gedrag van ChatGPT veel concreter maakt. Niet iedere vraag triggert namelijk hetzelfde zoekpad. Hoe dichter een vraag bij validatie, vergelijking of expertselectie komt, hoe meer extra zoekstappen het model meestal zet. Dat maakt fan-out niet alleen een technisch verschijnsel, maar ook een bruikbaar marketingkader.

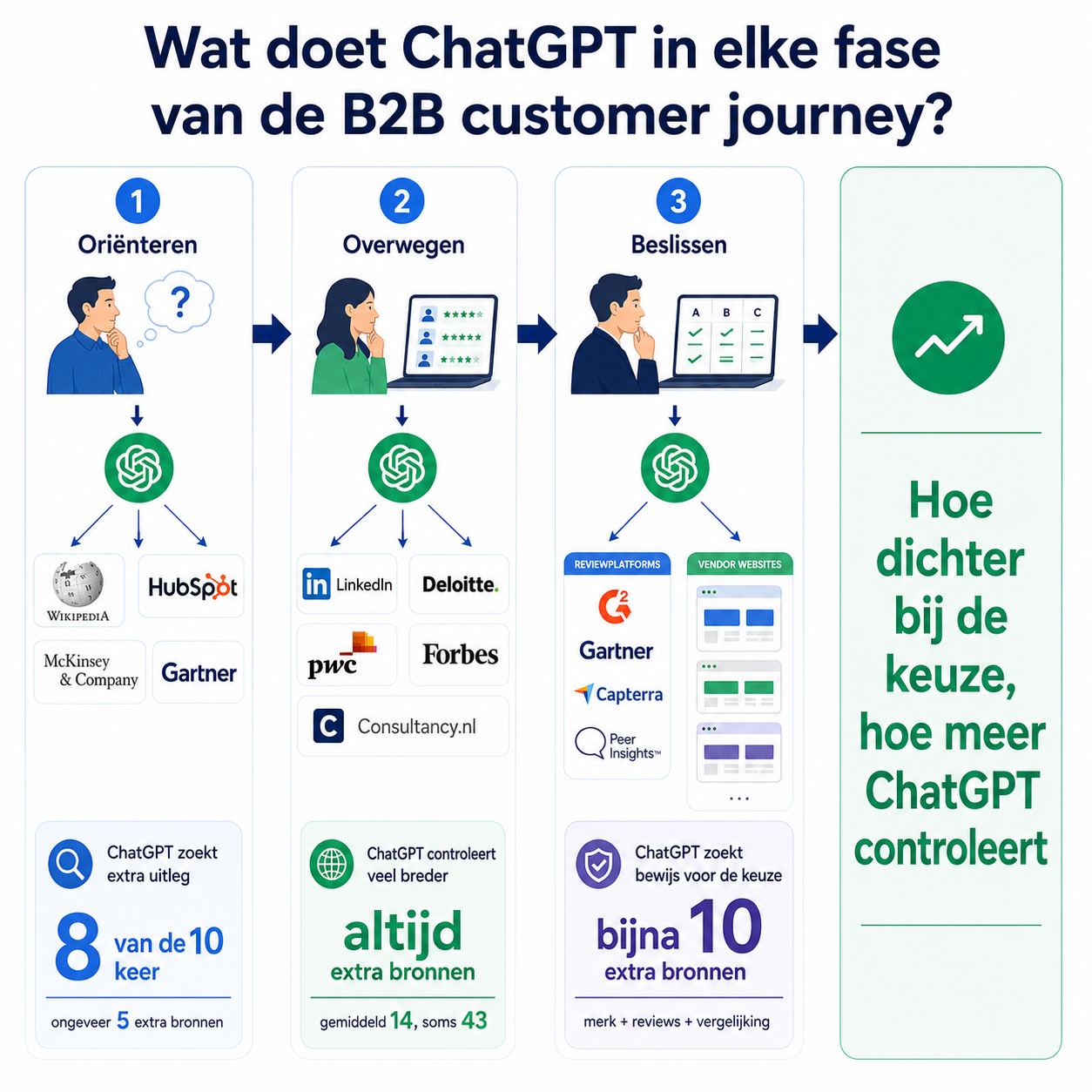
Fase 1: Oriëntatie
In de oriëntatiefase zie ik vooral definities en kennisvragen terug. Denk aan vragen als: wat is supply chain optimalisatie? of hoe werkt employer branding? Bij dit soort brede vragen leunt ChatGPT deels op bestaande modelkennis, maar in de data zie ik ook duidelijk dat het model vaak nog externe validatie zoekt. Bij definitievragen liet het in 82,4% van de runs fan-out zien, met gemiddeld 4,7 extra zoekopdrachten per run.
Wat daarbij opvalt, is dat ChatGPT vaak zoekt naar recente context en naar bronnen die een onderwerp helder uitleggen. In de onderliggende queryfamilies zie ik bijvoorbeeld regelmatig patronen als trend_year en site_search. Dat suggereert dat het model niet zomaar een standaarddefinitie wil geven, maar zijn antwoord wil actualiseren of controleren aan de hand van recente en gerichte bronnen.
Voor mij is de marketingles in deze fase vrij duidelijk. Als iemand zich nog oriënteert, moet mijn website of content in staat zijn om als betrouwbare kennisbank te functioneren. Heldere definities, actuele context en goed gestructureerde uitlegcontent helpen dan niet alleen voor SEO of thought leadership, maar vergroten ook de kans dat ChatGPT mijn content gebruikt om zijn basiskennis te toetsen en aan te vullen.
Fase 2: Overweging
In de overwegingsfase verschuift het gedrag van ChatGPT merkbaar. Hier zie ik veel vaker vragen over experts, consultants, gespecialiseerde partijen en partijen met zichtbare autoriteit. Bijvoorbeeld: wie zijn toonaangevende onafhankelijke HR-consultants? Juist in dit soort prompts piekt het zoekgedrag van de AI. Expertvragen triggerden in mijn dataset in 100% van de runs fan-out, met gemiddeld 13,7 extra zoekopdrachten en een maximum van 43 in één run.
Wat ik interessant vind, is dat het model hier niet simpelweg één bronsoort volgt. Bedrijfs- en vendor-sites blijven belangrijk; binnen expert-runs valt 53,3% van de gemeten sourcetypes in de categorie company_or_vendor_site. Tegelijk zie ik een duidelijke mix met persoonlijke profielen, consultancy-sites en vakmedia. Persoonlijke profielen vallen in 16,9% van de gemeten sourcetypes in social_profile, consultancy-sites in 10% en vakmedia in 9,9%. LinkedIn komt in deze zoekpaden geregeld terug, maar nooit als enige of dominante waarheid.
Daarom trek ik in deze fase ook geen simplistische conclusie als “alleen personal branding telt”. Wat ik wel zie, is dat een bedrijfswebsite alleen niet genoeg is. Als ik zichtbaar wil zijn in de overwegingsfase, moet mijn merk gekoppeld zijn aan herkenbare experts, aan publicaties in vakmedia en aan aanwezigheid op professionele netwerken. ChatGPT lijkt hier namelijk niet alleen te zoeken naar een bedrijfsnaam, maar vooral naar een geloofwaardige mix van expertise, herkenning en externe bevestiging.
Fase 3: Beslissing
In de beslissingsfase wordt het zoekgedrag van ChatGPT nog concreter. Hier zie ik vooral vergelijkingsvragen terug, zoals: hoe verhoudt software A zich tot software B? Dat soort prompts activeert een duidelijk validatiepad. Vergelijkingsvragen triggeren gemiddeld 9,48 extra zoekopdrachten per run. Dat is minder dan bij expertvragen, maar nog steeds fors.
Wat ik in deze fase vooral zie, is dat ChatGPT leveranciersteksten niet afwijst, maar ze ook niet op zichzelf laat staan. Binnen comparison-runs blijft 73,3% van de gemeten sourcetypes vendor-gedreven, maar tegelijk keren in de ruwe fan-out-queries ook G2, Gartner, Capterra en Peer Insights structureel terug. Dat betekent voor mij dat het model vendorinformatie probeert te trianguleren met onafhankelijke of semi-onafhankelijke validatie. Het zoekt dus niet alleen naar wat een merk over zichzelf zegt, maar ook naar wat derden daarover laten zien.
Daar zit meteen de belangrijkste marketingles van deze fase. Mijn eigen productpagina’s blijven belangrijk, want ook die worden door ChatGPT gebruikt. Maar zonder zichtbaarheid op review-platforms, vergelijkingssites en analistenomgevingen mis ik een essentieel deel van het pad waarlangs het model vertrouwen opbouwt. In AI-zichtbaarheid gaat het dus niet alleen om owned media, maar ook om de plekken waar mijn merk door anderen wordt gespiegeld, vergeleken en gevalideerd.
Zijn er verschillen tussen B2B-branches?
Die zijn er wel, maar kleiner dan ik vooraf misschien zou verwachten. In de dataset heb ik gekeken naar domeinen als GEO, SaaS, Supply Chain, HR en Marketing. Daarin zie ik nuanceverschillen, maar geen totaal andere logica. GEO heeft bijvoorbeeld een trigger rate van 97,8%, terwijl Supply Chain op 87,5% zit. Dat is relevant, maar niet het hoofdverhaal.
Het patroon dat ik overal terugzie, is dat promptintentie zwaarder weegt dan branche. Een vergelijkingsvraag over HR-software activeert in de kern dezelfde validatielogica als een vergelijkingsvraag over logistieke software. Een expertvraag in SaaS lijkt qua zoekgedrag veel sterker op een expertvraag in HR of GEO dan op een definitievraag binnen diezelfde SaaS-sector. Voor mij is dat een belangrijk inzicht, omdat het betekent dat ik AI-zichtbaarheid niet alleen per markt moet benaderen, maar vooral per type vraag en per fase in de journey.
De logica achter het gedrag: een E-E-A-T-achtige lens
Ik kan op basis van deze dataset niet bewijzen dat ChatGPT letterlijk een vast beoordelingsmodel volgt. Wat ik wel zie, is dat de fan-out-patronen sterk lijken op een E-E-A-T-achtige logica: Experience, Expertise, Authoritativeness en Trustworthiness. Die vergelijking met Google vind ik nuttig, niet omdat het hetzelfde systeem is, maar omdat het helpt om het gedrag van ChatGPT begrijpelijk te maken.
Als het model vendor-sites combineert met persoonlijke profielen, zie ik een zoektocht naar expertise. Als het review-platforms en vergelijkingsomgevingen gebruikt, wijst dat voor mij op experience en trust. En als het gericht binnen vertrouwde domeinen zoekt via site_search, zie ik daarin een voorkeur voor bronnen met gepercipieerde autoriteit. Ik zou dus niet zeggen dat ChatGPT “E-E-A-T toepast” in letterlijke zin, maar wel dat het zoekgedrag sterk wijst op een vergelijkbare validatielogica.
Mijn conclusie
Als ik deze analyse terugbreng tot één praktische conclusie, dan is het deze: zichtbaar worden in ChatGPT vraagt geen los trucje, maar een gelaagde aanpak. In de oriëntatiefase moet mijn domein functioneren als actuele kennisbasis. In de overwegingsfase moeten mijn experts, consultants of thought leaders ook buiten mijn eigen site zichtbaar zijn. En in de beslissingsfase moet mijn merk terugkomen in onafhankelijke review- en vergelijkingscontext.
Juist die combinatie maakt volgens mij het verschil. ChatGPT kijkt niet alleen naar wat ik zelf publiceer, maar ook naar hoe mijn merk terugkomt in het bredere web van expertise, validatie en vertrouwen. Hoe beter die lagen op elkaar aansluiten, hoe groter de kans dat het model mijn merk uiteindelijk presenteert als een geloofwaardig en bruikbaar antwoord.